9.18 レイヤ移動機能を拡張する(その4)
 |
今回は ExtendedMover クラス(画像を拡大・縮小・回転するクラスのことね)のコンストラクタを見ていくことにするね。 |
 |
え、コンストラクタだけ? |
|
そうだよ。 |
|
それだけだとすぐ終わっちゃわない? |
|
ぜーんぜん。むしろかなり長くなると思うよ。
今回は今までで一番長くなるんじゃないかな。 |
|
えっ、そーなの? |
|
何で長くなるのかは LinearMover
クラスのコンストラクタを見ればわかると思うよ。 |
|
LinearMover クラス…って
move タグで使われてるクラスだったよね? |
|
そ。レイヤを移動させたり不透明度を変えたりするクラスだよ。
で、その LinearMover クラスのコンストラクタはこんなふうになってるの。 |
<LinearMover クラスのコンストラクタ(DefaultMover.tjs より抜粋)>
function LinearMover(layer, path, time, accel, finalfunction)
{
this.layer = layer;
this.path = path;
this.time = time;
this.accel = accel;
this.finalFunction = finalfunction;
totalTime = (pointCount = (path.count \ 3 - 1)) * time;
}
|
コンストラクタの中身はいじらないから置いとくとして、引数の方に注目してみて。 |
|
えっと、5つ引数があって、それぞれ layer, path, time, accel, finalfunction っていう名前になってるね。 |
|
layer と time と
accel の意味は大体見当がつくでしょ? |
|
move タグの layer 属性と
time 属性と accel 属性、かな? |
|
ん、そのとーり。 |
|
※第1引数の layer は、move タグの layer 属性と page 属性によって決まります。
例えば、“layer=0 page=fore”と指定した場合、第1引数の layer は kag.fore.layers[0] になります。 |
|
あと path って move タグの path 属性なんじゃないの? |
|
確かに第2引数の path
にはレイヤの位置(left,top)と不透明度(opacity)がどんなふうに変化するかを表すデータが入ってるんだけど、
この path は "(100,200,255)"
みたいな文字列じゃなくって配列になってるんだ。 |
|
配列? |
|
ん、配列だよ。 |
|
それってどんな配列なの? |
|
んー、そーだね…これは例を見た方がわかりやすいかな。
例えば、こんなふうに image タグと
move タグを実行したとするね。 |
<image タグと move タグの実行例>
[image layer=0 page=fore storage="krkr" left=100 top=450 opacity=255]
[move layer=0 page=fore time=1000 path="(200,350,192)(300,250,128)(400,150,64)"]
|
move タグを実行する前、
つまり image タグを実行した直後の
0 番の前景レイヤの位置と不透明度はどうなってる? |
 |
位置が (100,450) で不透明度が 255 だね。 |
|
んじゃ move タグを実行すると? |
|
ん〜っと…time 属性が 1000 だから、
1秒後に (200,350) の位置に移動して不透明度が 192 になるね。
それから、2秒後には (300,250) の位置に移動して不透明度が 128 になって、
3秒後に (400,150) の位置に移動して不透明度が 64 になって終わりだね。 |
|
だね。
こんなふうに move タグを実行する時は、
LinearMover クラスのコンストラクタの path はこういう配列になるんだ。 |
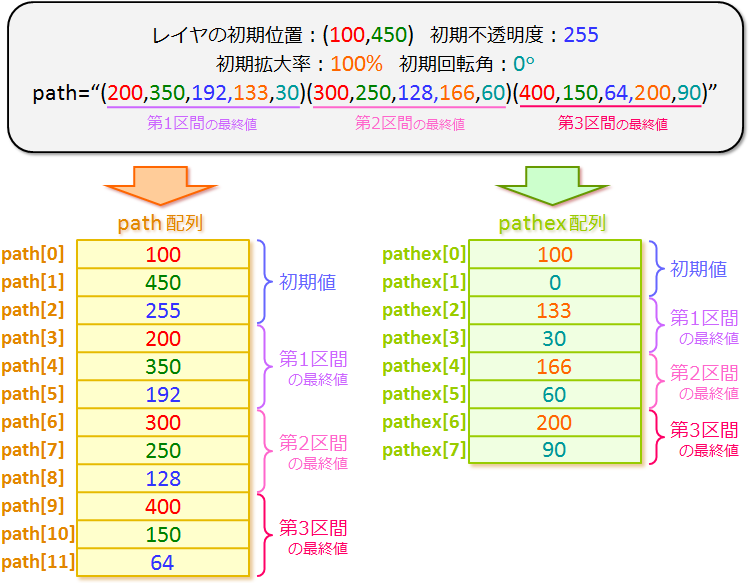
<このスクリプト に対応する path 配列の中身>
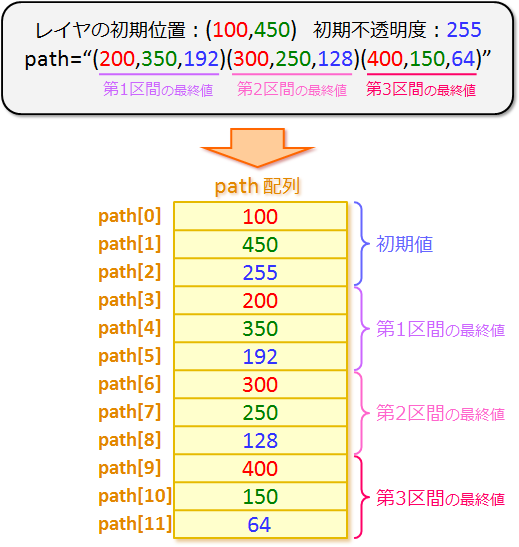
|
path 配列の 0 番目の要素(path[0])が left の初期値
100 で、1 番目の要素(path[1])が
top の初期値 450で、
2 番目の要素(path[2])が不透明度の初期値
450で…って感じで、全部で 12 個の要素がある配列になってるわけね。 |
|
えっと、じゃあ path のそれぞれの要素に
left とか top とか不透明度の値が入ってるってこと? |
|
そうそう。
path[0], path[1], path[2] にそれぞれ
left, top, opacity(不透明度)の初期値が入ってて、
path[3], path[4], path[5] に第1区間の
left, top, opacity の最終値が入ってて、
path[6], path[7], path[8] に第2区間の
left, top, opacity の最終値が入ってて、
path[9], path[10], path[11] に第3区間の
left, top, opacity の最終値が入ってるの。 |
|
第1区間の最終値とか第2区間の最終値ってなに? |
|
第1区間ってのはレイヤが動き始めてから1秒後までのことだよ。
だから第1区間の left, top, opacity
の最終値は1秒後のレイヤの位置とか不透明度のことね。 |
|
へぇ、そーいうのって第1区間の最終値とか言うんだ? |
|
いや、特に呼び方がないみたいだから、とりあえず勝手にそう呼ぶことにしただけだよ。 |
|
あ、そーなんだ…
ところで、なんで位置とか不透明度の値をわざわざ配列にしてるの? |
|
配列にしといた方が後々計算がやりやすくなるからね。
ちなみに beginMove メソッドが
path属性(move
タグの中に書く文字列の方ね)を path配列 に自動的に変換してくれてるから、
move タグを使う時には配列のことは意識しなくてもいいわけね。 |
|
※beginMove メソッドについては §9.17 参照。 |
|
そーなんだ。 |
|
じゃ path 配列の話は一旦置いといて、
LinearMover クラスのコンストラクタの話に戻るね。
あと残ってるのは第5引数の finalfunction かな。 |
|
move タグに finalfunction 属性なんてないよね? |
|
これだけは属性と直接関係ない引数だからね。 |
|
そなの? |
|
うん。finalfunction はメソッドの参照になってて、stopMove メソッドが呼び出された時に finalfunction
が呼び出されるようになってるの。
ちなみに finalfunction は wm
タグに関係があるんだけど、どんなメソッドかわかる? |
|
※メソッド(関数)への参照については §1.19 参照。
また、stopMove メソッドについては §9.17 参照。 |
|
wm タグに関係があるメソッドねぇ…
う〜ん、なんだろ…? |
|
§9.16で、レイヤの移動が終わったら
KAG システムに「wm タグで待つのをやめてシナリオの実行を再開して」って伝えなくちゃいけないって言ったのは覚えてる? |
|
うん、前回も言ってたよね、それ。
…あ、もしかして finalfunction ってそれを伝えるメソッドってこと? |
|
そのとーり。
stopMove メソッドでレイヤの位置と不透明度を最終値に設定した後
finalfunction を呼び出すことで、
KAG システムが wm タグで待つのをやめてシナリオの実行を再開するようになってるんだ。 |
|
へぇ、そーなんだ。 |
|
※move タグでは、
finalfunction は KAGLayer クラスの moveFinalFunction メソッドへの参照となります。さらに、moveFinalFunction メソッドが KAGWindow クラスの onLayerMoveStop メソッドを通じて、Conductor クラス(シナリオ実行を管理するクラス)の trigger メソッドを呼び出すことにより、wm タグを抜けてシナリオの実行が再開されます。
(finalfunction については拡張の必要がないため、詳細な説明を割愛させて頂きます) |
|
で、ここまでが前置きね。 |
 |
え、今までのって前置きだったの? |
|
ん、こっからが本題の ExtendedMover クラスのコンストラクタの話だよ。 |
|
うわ、ホントに今回は長くなりそーな感じ… |
|
じゃ ExtendedMover クラスのコンストラクタを見ていくね。 |
<ExtendedMover クラスのコンストラクタ>
function ExtendedMover(layer, elm)
{
this.layer = layer;
time = +elm.time;
var loadParams = getLoadParams(layer);
parsePath(elm, loadParams);
currentScale = pathex[0];
currentAngle = pathex[1];
}
 |
なんか見た目はそんなにフクザツそーには見えないよねぇ… |
|
その辺は見ていけばわかるよ。
まず最初はレイヤへの参照を layer
っていうメンバ変数に代入して(この layer は
LinearMover クラスのコンストラクタの第1引数の
layer とおんなじだよ)、
exmove マクロの
time 属性に指定されてる値を
time っていうメンバ変数に代入してるんだ。
ちなみに引数の elm は exmove
マクロに指定されてる属性の値が記録してある辞書配列(つまり mp のことだね)だよ。 |
|
※mp については §4.8 参照。 |
|
ExtendedMover クラスのコンストラクタの引数って
LinearMover クラスのコンストラクタの引数と違うんだね。 |
|
ん、ExtendedMover クラスのコンストラクタに必要なのは
path 属性と time
属性の情報だけだから、どっちも elm から直接取得することにしたんだ。 |
|
ふぅん。 |
|
じゃ次いくね。
次にレイヤの loadParams を取得してるんだけど、
loadParams は覚えてる? |
|
ん〜っと…確か eximage マクロを作った時に出てきたよね。
なんか属性の値が入ってる辞書配列、みたいな感じじゃなかったっけ? |
|
もちょっと正確に言うと、loadParams は
image タグで画像を読み込んだ時に指定されてた属性が記録されてる辞書配列だね。 |
|
※§9.11 参照。 |
|
あ、そーそー。そんな感じだったよね。 |
|
ただ、前は onStore メソッドとか
onRestore メソッドの引数 f を使って、
例えば“f.foreCharacterLayers[0].loadParams”みたいにすれば
0 番の前景レイヤの loadParams が取得できたけど、
今回はどっちのメソッドも無いから、前とはちょっと違ってるんだけどね。 |
|
そーいえばそーだね。
でも 0 番の前景レイヤだったら“kag.fore.layers[0].loadParams”でいーんじゃないの? |
|
ん〜、考え方は合ってるんだけど、
kag.fore.layers[0] には
loadParams っていうメンバ変数とかプロパティは無いんだよね。 |
|
え、じゃあ kag.fore.layers[0].loadParams じゃダメってコト? |
|
うん。
レイヤオブジェクトから直接 loadParams を取得する場合はこうするの。 |
<前景レイヤの loadParams を取得する getLoadParams メソッド>
function getLoadParams(layer)
{
var index = kag.fore.layers.find(layer);
if(index != -1)
return kag.fore.layers[index].Anim_loadParams;
index = kag.back.layers.find(layer);
if(index != -1)
return kag.back.layers[index].Anim_loadParams;
return void;
}
|
このメソッドは引数に指定されてる layer が前景レイヤだったら、
そのレイヤの loadParams を返すメソッドだよ。
ちなみに前景レイヤ以外が指定されてたら void を返すようになってるよ。 |
|
“kag.fore.layers[index].Anim_loadParams”って書いてあるけど、
これが loadParams なの? |
|
そ。kag.fore.layers の要素から loadParams
を取得する時は“loadParams”じゃなくって“Anim_loadParams”になるの。 |
|
※Anim_loadParams は前景レイヤ(CharacterLayer クラス)のスーパークラス(GraphicLayer クラス)のスーパークラス(AnimationLayer クラス)で定義されているメンバ変数です。 |
|
ふーん、何で違う名前になってるの? |
|
さぁ、なんでだろーねー? |
|
え、何か意味があるんじゃないの? |
|
ん〜、よくわからないけど、Anim_loadParams は
AnimationLayer っていうクラスのメンバ変数になってて、
AnimationLayer クラスのメンバ変数の名前には全部最初に“Anim_”がついてるからかなぁ?
まぁ Anim_loadParams っていう名前でも全然問題ないわけだし、
特に気にしなくていいと思うよ。 |
|
そっか、わかった。 |
|
あと、getLoadParams メソッドの中身は
eximage マクロを作った時に出てきた
isCharacterLayer メソッドとか
getLayerInfo メソッドとほとんどおんなじだから、
説明は省略させてもらうね。 |
|
確かによく似てるみたいだね。
うん、りょーかい。 |
|
それじゃコンストラクタの話に戻るね。 |
|
getLoadParams メソッドの次にある
parsePath ってメソッド? |
|
そうだよ。これが今回のメイン、path 属性から
path 配列を作るメソッドだよ。 |
|
えっ? でもそれってさっき beginMove メソッドがやってくれるって言ってたよね? |
|
move タグの場合はね。
でも exmove マクロの path 属性は
move タグの path 属性と書き方が違ってるでしょ? |
|
うん、拡大率とか回転の角度も指定できるようになってたよね。 |
|
beginMove メソッドは、当然 path
属性には位置と不透明度の情報しか書かれてないって思って path 属性を処理するわけだから、
拡大率とか回転角の情報が書いてあると beginMove メソッドは使えないんだ。
つまり、拡大率とか回転角を指定できるようにしようと思ったら、自前で path 属性を処理して
path 配列を作らなくちゃいけないってワケ。
で、それをやるのが parsePath メソッドなの。 |
|
そーなんだ…なんかタイヘンそうだね。 |
|
ん、これがコンストラクタで一番タイヘンなとこだね。
ってワケで parsePath メソッドは結構長いから、
先にコンストラクタを最後まで見とくことにするね。 |
|
えっと、あと残ってるのは…“currentScale = pathex[0];”と“currentAngle = pathex[1];”ってのだけみたいだけど、これってどーゆー意味なの? |
|
まず、currentScale と currentAngle
ってのは ExtendedMover クラスのメンバ変数で、
それぞれ現在の拡大率と回転角を表してるんだ。
これはまた後で出てくるから、詳しいことはその時に説明するね。 |
|
そーなんだ。わかった。
じゃあ、pathex っていうのは? なんか配列みたいだけど? |
|
さっき move タグの path 属性は
path 配列に変換されて、
path 配列の要素に left とか
top とか不透明度の値が入るって言ったでしょ。 |
|
うん。 |
|
pathex ってのは、exmove マクロの
path 属性に書いてある拡大率と回転角が入ってる配列なんだ。 |
|
拡大率と回転角って path 配列に入れるんじゃないの? |
|
さっきも言ったように、LinearMover クラスのコンストラクタに渡す
path 配列は left, top, opacity
の順番に値が入ってなくちゃいけないから、
path 配列に拡大率と回転角も入れちゃったらまずいでしょ。 |
|
あ、そっか。 |
|
だから、拡大率と回転角の情報を入れる専用の配列を作ってるの。
それが pathex なわけね。
ちなみに exmove マクロの場合は
こんなふうに path 属性から
path 配列と pathex 配列を作ってるんだ。 |
<eximage タグと exmove タグの実行例>
[eximage layer=0 page=fore storage="krkr" left=100 top=450 opacity=255 scale=100 angle=0]
[exmove layer=0 page=fore time=1000 path="(200,350,192,133,30)(300,250,128,166,60)(400,150,64,200,90)"]
<上記のスクリプトに対応する path, pathex 配列の中身>
|
pathex 配列の作り方は基本的に path 配列と同じで、
この例の場合だと、pathex[0] と pathex[1]
がそれぞれ拡大率と回転角の初期値になってるんだ。
で、pathex[2] と pathex[3]
が第1区間の拡大率と回転角の最終値になってて、
pathex[4] と pathex[5]
が第2区間の拡大率と回転角の最終値になってて、
pathex[6] と pathex[7]
が第3区間の拡大率と回転角の最終値になってるの。 |
|
なるほどねぇ。 |
|
じゃこれでコンストラクタの中身は一通りチェックしたから、
次は parsePath メソッドを見てくね。 |
<parsePath メソッド>
function parsePath(elm, loadParams = %[])
{
pathex[0] = loadParams.scale !==
void ? (
int +loadParams.scale) : 100;
pathex[1] = loadParams.angle !==
void ? (
int +loadParams.angle) : 0;
var paths = [].split(
"()", elm.path, ,
true);
var args = [], a, i, n;
var initScale = pathex[0], initAngle = pathex[1];
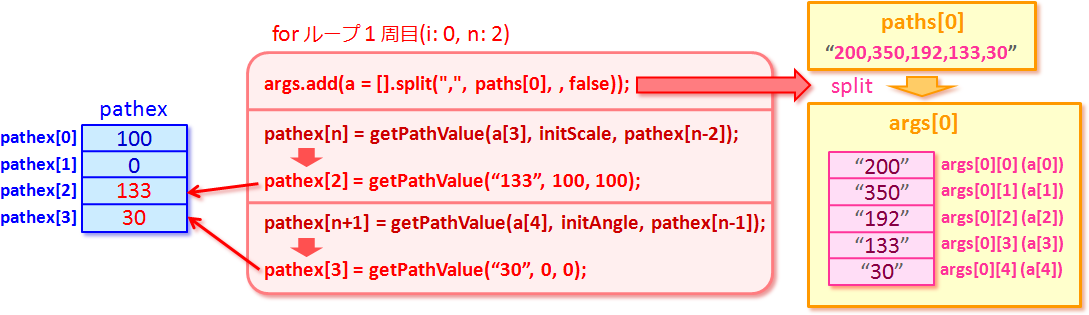
for(i=0,n=2;i<paths.count;i++,n+=2)
{
args.add(a = [].split(",", paths[i], , false));
pathex[n] = getPathValue(a[3], initScale, pathex[n-2]);
pathex[n+1] = getPathValue(a[4], initAngle, pathex[n-1]);
}
var path = _path;
path[0] = layer.left;
path[1] = layer.top;
path[2] = layer.opacity;
for(var i=2;i<pathex.count;i+=2)
{
if(pathex[i+1] != initAngle)
{
moveFunc = rotate;
break;
}
if(pathex[i] != initScale)
{
if(initAngle != 0)
{
moveFunc = rotate;
break;
}
moveFunc = resize;
}
}
if(moveFunc !== void && loadParams.storage !== void)
{
refLayer = new Layer(layer.window, layer);
refLayer.loadImages(loadParams.storage);
var params = %[];
calcRotateParams(params, refLayer, pathex[1] * radConst, pathex[0] / 100);
path[0] += params.dspX;
path[1] += params.dspY;
}
var initLeft = path[0], initTop = path[1], initOpacity = path[2];
for(i=0,n=3;i<paths.count;i++,n+=3)
{
a = args[i];
path[n] = getPathValue(a[0], initLeft, path[n-3]);
path[n+1] = getPathValue(a[1], initTop, path[n-2]);
path[n+2] = getPathValue(a[2], initOpacity, path[n-1]);
}
}
※09/04/12 追記:
メンバ変数“pointCount”が不要となったため削除しました。
|
ホントに長いね、コレ… |
|
まぁこのメソッドの中で path 配列と pathex
配列の両方を作ってるしね。
じゃまずは pathex 配列を作ってるとこから見てくね。 |
|
最初に pathex[0] と pathex[1]
に値を代入してるみたいだけど、これって拡大率と回転角の初期値だったよね? |
|
ん、だから pathex[0] の方は loadParams.scale
をチェックしてて、pathex[1] の方は loadParams.angle
をチェックしてるわけね。 |
|
この scale とか angle って
eximage マクロの scale 属性と
angle 属性だっけ? |
|
そうだよ。exmove マクロを実行する前に
eximage マクロで画像が読み込まれてて、
さらに scale 属性が指定されてれば“loadParams.scale !== void”が真になるの。
その時は exmove マクロを実行する前の画像の拡大率が scale
属性に指定した値になってるから、pathex[0] に loadParams.scale
の値を数値にして代入してるんだ。 |
|
それじゃ exmove マクロを実行する前に
eximage マクロで angle
属性を指定して画像を読み込んでたら“loadParams.angle !== void”が真になるから、
その時は pathex[1] に loadParams.angle
の値を代入してるってことかな? |
|
ん、そういうこと。
あと loadParams.scale が void ってことは、
画像の拡大とか縮小をしてないってことだから、pathex[0] は
100(%) になるよね。 |
|
loadParams.angle が void
だったら回転してないから pathex[1] は 0(°)
になるんだね。 |
|
※前景レイヤ以外に対して exmove マクロを実行した場合は、
getLoadParams メソッドが void を返すため
loadParams は第2引数のデフォルト値が適用されて %[](空の辞書配列)になり、
loadParams.scale と loadParams.angle はどちらも void となります。 |
|
そう。じゃ次いくね。
こっからがちょっとややこしくなるんだけど、この
for ブロックの中で
pathex[2] から先の要素に path
属性に指定されてる拡大率と回転角を代入してってるんだ。 |
|
えっと、その前に for ブロックの前にある“path = [].split("()", elm.path, , true);”ってゆーのがよくわかんないんだけど? |
|
そーだね、まずそこから説明しなくちゃね。
split ってのは Array
クラス(配列のクラスのことね)のメソッドで、文字列を分割するメソッドなんだ。 |
|
※Array クラスについては §1.14 参照。 |
|
文字列を分割するってどーいうコト? |
|
んー、これはちょっと説明が難しいから、例を見てみよっか。
まず、こういうスクリプトを実行するとするね。 |
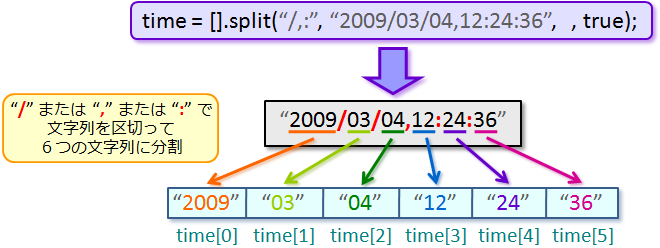
<split メソッドの使用例(その1)>
var time = [].split("/,:", "2009/03/04,12:24:36", , true);
※上記のスクリプトは以下のように書いても同じ意味になります
var time = new Array();
time.split("/,:", "2009/03/04,12:24:36", , true);
|
split メソッドの第1引数と第2引数にそれぞれ
"/,:" っていう文字列と
"2009/03/04,12:24:36" っていう文字列が指定されてるでしょ。 |
|
うん、そーだね。 |
|
これは「"2009/03/04,12:24:36" っていう文字列を
"/"(スラッシュ)とか ","(コンマ)とか
":"(コロン)で区切って分割する」っていう意味なんだ。 |
|
う〜ん、まだちょっとよくわかんないんだけど… |
|
"2009/03/04,12:24:36" っていう文字列の中の
"2009" の隣に "/"(スラッシュ)があるでしょ。 |
|
うん。 |
|
だから、まず "2009" の所で文字列が区切られるの。
で、次に "03" の隣にも "/" があるよね。 |
|
あるね。 |
|
だから、今度は "03" の所で文字列が区切られるんだ。
ここまでで "2009" と "03"
っていう2つの文字列が出来てるってのを覚えといてね。
それから、次に "04" の隣に ","(コンマ)があるから、
ここでも文字列が区切られて… |
|
"04" っていう文字列が出来るってコト? |
|
そうそう。後は同じようにして、"12"、"24"
の隣には ":"(コロン)があるからここでも文字列を区切って、
あと最後に "36" が残るからこれも区切られるわけね。 |
|
え〜っと…じゃあ結局、元々の文字列が "2009"、"03"、
"04"、"12"、
"24"、"36"
っていう6個の文字列に区切られたってことになるのかな? |
|
そうだね。
で、その6つの文字列が time
っていう配列の要素(time[0]〜time[5]だね)にそれぞれ代入されるの。
つまり、こんな感じになるわけね。 |
<split メソッドによる文字列の分割>
|
time[0] が "2009" っていう文字列になってて、
time[1] が "03" っていう文字列になってて…って感じ? |
|
そう。そんなに難しくはないでしょ? |
|
うん、まーやってることは大体解るよ。 |
|
じゃ split メソッドについてはこれで OK かな? |
|
あ、ちょっと待って。
第3引数と第4引数って何に使ってるの? |
|
あー、そう言えば説明がまだだったね。
まず、第3引数は何にも使われてないよ。 |
|
え、何にも使われてないって…? |
|
split メソッドの第3引数は“これから先 TJS
がバージョンアップした時に何かに使うかもしれないから予約してる引数”なんだ。
けど、今のところ何にも使われてないから、第3引数には何も指定しなくていいの。
つまり引数を省略しといて OK ってことね。 |
|
へぇ、そーなんだ。 |
|
で、第4引数は“空の要素を無視するかどうか”を指定するようになってて、
空の要素を無視する場合は true で、
無視しない場合は false を指定するの。 |
|
空の要素って? |
|
んー、これも例があった方がいいかな。
例えば、こういうスクリプトを実行したとするね。 |
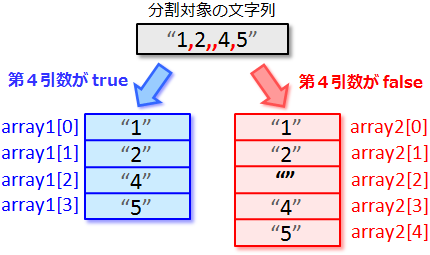
<split メソッドの使用例(その2)>
var array1 = [].split(",", "1,2,,4,5", , true);
var array2 = [].split(",", "1,2,,4,5", , false);
|
このスクリプトは "1,2,,4,5" っていう文字列を
","(コンマ)で分割してるんだけど、
"3" が抜けてて "," が2個続いてるでしょ。 |
|
うん、そーだね。 |
|
こんなふうに、第1引数に指定してる文字(この例の場合は
"," ね)が2つ以上連続してる時に、
split メソッドの第4引数に true
を指定するか false を指定するかで結果が変わってくるんだ。 |
|
どんなふうに変わるの? |
|
第4引数が true だと、
"2" と "4"
の間みたいに何も文字が無いとこは無視されるから、
"1"、"2"、"4"、"5" の4つの文字列に分割されるの。 |
|
じゃあ第4引数が false だったら、
"1"、"2"、"3"、"4"、"5" に分割されるとか? |
|
必ずしも "2" と "4" の間に
"3" が入るとは限らないし、
"1,2,,A,B" とかだったら
"2" と "A" の間に何が入るかわかんないでしょ。 |
|
あ…確かにそーだね。
じゃあ第4引数が false だったらどーなるの? |
|
"2" と "4"
の間に空文字列が入るの。 |
|
空文字列? |
|
そ。"2" と "4" の間には何も文字が無いわけだから、
何も文字が無いっていう状態を表す空文字列("")が分割後の配列の2番目の要素(array2[2])に入るの。こんなふうにね。 |
<第4引数に true と false を指定した時の split メソッドの動作の違い>
|
なるほどねぇ…でも文字が無いとこに空文字列を入れる意味なんてあるの? |
|
もちろん。
parsePath メソッドの中でも第4引数を false
にして split メソッドを呼び出してるとこがあるしね。 |
|
そーなの? |
|
まぁそれはまた後で見ていくとして、
とりえあず parsePath メソッドの
pathex 配列を作るとこに戻るね。 |
|
はーい。
…あ、ホントだ。for ブロックの中で split
メソッドを呼び出してるとこは第4引数が false になってるね。 |
|
でしょ。
その前に、ここで split メソッドを呼び出すと、“(”と“)”で
path 属性に指定されてる文字列(elm.path)を分割して、
あと第4引数が true で文字が無いとこは無視するから、
paths っていう配列の中身はこうなるよね。 |
<path 属性の分割>
|
paths[0] と paths[1] と
paths[2] がそれぞれ第1、第2、
第3区間の位置と不透明度と拡大率と回転角の最終値になるんだね。 |
|
そういうこと。
じゃ for ブロックの中の split
メソッドを呼び出すとどうなるかわかる? |
|
えっと、その前に split メソッドを呼び出してる行のスクリプトがよくわかんないんだけど… |
|
あー、a に split
メソッドの戻り値を代入するのと args の
add メソッドを呼び出すのを1行でやっちゃってるから、
ちょっとわかりにくかったかな。
この行はね… |
|
※Array (配列)クラスの add メソッドについては §1.14 参照。 |
<この行と同じ意味のスクリプト>
a = [].split(",", paths[i], , ,false);
args.add(a);
|
こんなふうに、add メソッドの括弧の中身が先に実行されて、
その後 add メソッドが呼び出されるの。
これで大丈夫かな? |
|
うん、おっけー。
つまり、最初に“a = [].split(",", ,paths[i], , ,false);”が実行されて、
paths[i] を ","
で区切った文字列の配列が a になるんだね。 |
|
ん、そうだね。
じゃあとりあえず“a = [].split(",", paths[0], , ,false);”を実行するとどうなるかな? |
|
んーっと、paths[0] は
"200,350,192,133,30" になってて、それを
"," で分けるんだから… |
<“a = [].split(",", paths[0], , ,false);”実行後の a 配列の中身>
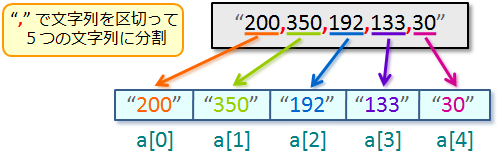
|
こんな感じかな? |
|
ん、そうなるね。
で、この a 配列を add メソッドで
args っていう配列の要素として追加するから、
args は2次元配列になるよね。 |
|
2次元配列…って確か配列の要素がまた配列になってるののことだったよね? |
|
※2次元配列については §8.8 参照。 |
|
そうだよ。
args[0] が a とおんなじになるから、
args[0][0] が "200"、
args[0][1] が "350"、
args[0][2] が "192"…って感じになるね。 |
|
args[0] が a だから、
args[0][0] の args[0]
の部分を a に置き換えると a[0]
になるって考えればいいんだよね? |
|
ん、そういうふうにも考えられるね。
じゃ次の行見てみよっか。 |
|
getPathValue ってメソッドだよね? |
|
そうだよ。
a 配列の要素は文字列だけど、
pathex 配列の要素は数値になるから、
getPathValue メソッドを呼び出すことで文字列を数値に変換してるんだ。 |
|
そっか…
ん? そーいえば文字列から数値に変換するのって“+”演算子でできるんじゃなかったっけ? |
|
※単項 + 演算子については §1.6 参照。 |
|
例えば "200" とかの文字列なら +"200" で数値の 200 になるけど、
exmove マクロは path
属性を拡張してて、数字以外も指定できるようにしてたでしょ。 |
|
数字以外を指定…? |
|
例えば "@+100" で“初期値+100”とか、
"$-50" で“前の区間の最終値-50”とか。
あと "f.x+10" みたいに変数も使えるようにしてたよね。 |
|
あー、確かにそーだったね。 |
|
+"@+100" とかやっても“初期値+100”にはならないからね。
そういう書き方に対応できるように getPathValue メソッドを作ってるの。 |
|
えっと、じゃあ例えば getPathValue メソッドの引数に
"@+100" って指定したら“初期値+100”の値が返ってくるってコト? |
|
そうそう。ま、他にも引数は必要だけどね。 |
|
なんかそれってすごい難しそーじゃない? |
|
新しいクラスとかメソッドは出てくるけど、別にそんな難しくはないよ。 |
|
ホントに? |
|
だって書こうと思えば2行で書けちゃうもん。 |
|
えっ、そんなに短く書けるの? |
|
うん。
こんなふうに2行で書けるよ。 |
<getPathValue メソッド>
function getPathValue(val, init, prev)
{
if(val == "") return prev;
return Scripts.eval(val.replace(new RegExp("[@]", "g"), string init).replace(new RegExp("[$]", "g"), string prev));
}
|
な、なんか return の行がすごいややこしーんだけど… |
|
だよね。
だから exmove_simple.ks の中ではもうちょっとわかりやすくこんなふうに書いてるんだ。 |
<getPathValue メソッド(上のスクリプトと同じ動作をします)>
|
確かにこっちのがわかりやすそーだけど、replace とか RegExp
とか eval とか見たことないのが色々あるねぇ。 |
|
replace メソッドと RegExp
クラスは初めて出てくるけど、eval
メソッドは前に使ったことあるよ。 |
|
あれっ、そーだっけ? |
|
まぁそれは後でチェックするとして、とりあえず最初の行から見てくね。 |
|
“if(val == "")”ってことは…
第1引数の val が空文字列かどうかチェックしてるんだね。 |
|
第1引数には args[0][0] とかが指定されるんだけど、
args[0][0] はさっき出て来たから、どんな値かはわかるよね? |
|
んと、確か args[0] は第1区間の最終値の文字列で、
args[0][0] はその最初の要素だから…
第1区間の left の最終値、かな? |
|
ん、そうだね。
つまり、第1引数に args[0][0] が指定された場合は、第1区間の
left の最終値を文字列から数値に変換するってことだね。 |
|
ねぇ、第1引数って空文字列になることあるの? |
|
exmove マクロの path
属性は "(,350,192,133,30)" っていうふうに、値の省略もできるようにしたでしょ? |
|
うん、そーだったね。 |
|
じゃ第1区間の最終値を表す文字列が
",350,192,133,30" だったら、
args[0][0] はどーなると思う? |
|
え? えーっと……どーなるんだっけ?? |
|
それじゃ、split メソッドの第4引数に false
を指定すると、文字列を分割した後に文字が無いとこはどうなるんだった? |
|
空文字列になるんだったよね? |
|
つまり args[0][0] は空文字列になるから、
第1引数が空文字列になることもあるの。 |
|
あ、なるほど。 |
|
ってワケで、値が省略されてたら“val == ""”が真になって第3引数の prev が返るのね。 |
|
prev って何の値なの? |
|
prev はね、1つ前の区間の値だよ。
exmove マクロの path
属性は値を省略すると1つ前の区間の値と見なしてるからね。
ちなみに1つ前の区間が無いときは prev は初期値になるよ。 |
|
そっか……うーん、path 属性って色々拡張されてたから、
あんまりよく覚えてないかも… |
|
ん〜、まぁ色んな書き方ができるようにしようと思ってちょっと拡張し過ぎちゃったかなって気はするけどね。
じゃあ次は replace メソッドを呼び出してるとこね。
replace メソッドは“@”を初期値に置き換えたり、“$”を1つ前の区間の値に置き換えたりするために使ってるんだ。 |
|
置き換える? |
|
例えば… |
<replace メソッドの使用例>
[iscript]
var before = "@+100";
var after = before.replace(new RegExp("[@]", "g"), "50");
System.inform(before + " → " + after);
[endscript]
|
このスクリプトを first.ks に書き込んで実行してみて。 |
|
う、うん。わかった。 |
<実行結果>
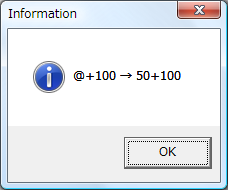
|
“@+100 → 50+100” って表示されたね。 |
|
つまり、replace メソッドを呼び出すことで、
“@”の部分が "50"
に置き換えられたわけね。 |
|
あ、なるほど。
ってことは…"50"
のとこを初期値にしとけば“@”が初期値に置き換えられるってこと? |
|
ん、そーいうこと。
ちなみに replace メソッドの第1引数が置き換える対象の正規表現パターンで、
第2引数が置き換えた後の文字列だよ。 |
|
正規表現パターンって? |
|
んー、正規表現パターンってのは文字列を検索したり置き換えたりする時に使われる表現法なんだけど、
とても一言じゃ説明しきれないから、とりあえず今は第1引数に“new RegExp("[@]", "g")”を指定すると“@”が置き換えられる対象になって、“new RegExp("[$]", "g")”を指定すると“$”が置き換えられる対象になるって思っといて。
あと、RegExp っていうのは正規表現を扱うクラスなんだけど、
これも詳しい説明は省略させてもらうね。 |
|
そーなんだ、わかった。 |
|
じゃ getPathValue メソッドに戻って…
第2引数の init ってのは初期値を表してるから、
この行で“@”を初期値に置き換えて、
それからこの行で“$”を前の区間の値(prev)に置き換えてるの。 |
|
第2引数に string が付いてるんだけど、これって何の意味があるの? |
|
replace メソッドの第2引数は文字列なんだけど、
init とか prev は数値になってるから、
string 演算子で文字列型に変換してるの。
…まぁ別に変換せずに数値のまま指定してもちゃんと置き換えられるんだけど、一応ね。 |
|
※string 演算子については §1.6 参照。 |
|
ふぅん、そっか。 |
|
これで置き換えができたから、最後に Scripts クラスの
eval メソッドを呼び出せば OK。 |
|
えっと、Scripts.eval メソッドって前にも出てきたんだったよね…? |
|
§7.4 で使ったよね。 |
|
どんなメソッドなんだっけ? |
|
前にも言ったけど、eval メソッドって名前から予想できるんじゃない? |
|
あ、確か eval メソッドって
eval タグとおんなじ意味のメソッドじゃなかった? |
|
そ。だから、例えば“Scripts.eval("tf.x = 1 + 2");”を実行しても“[eval exp="tf.x = 1 + 2"]”を実行しても
tf.x に 3 が代入されるわけね。 |
|
※eval タグは内部で“Scripts.eval(elm.exp);”を実行しています(elm は eval タグに指定されている属性を格納している配列です) |
|
eval メソッドの引数と
eval タグの exp 属性が対応してるんだよね。 |
|
ん、だから path 属性に変数が入ってても
eval タグを呼び出せばちゃんと変数の値が計算できるの。 |
|
なるほどねー。 |
|
んじゃ parsePath メソッドの
for ブロックの話に戻るね。 |
|
あー、そーいえば for ブロックの中身を見てたんだっけ。 |
|
ちょっと今回は話が色んなとこに飛んじゃっててわかりにくくなってるから、
もう一回 for ブロックの中身でやってることを確認しとくね。 |
|
りょーかい。 |
|
まず、path 属性(elm.path)が
"(200,350,192,133,30)(300,250,128,166,60)(400,150,64,200,90)"
だったら、この for ブロックで何回ループするかわかる? |
|
えっと、for ループを始める前に実行する式のとこに“i=0,n=2”って書いてあるけど、
普通は “i=0” って書くよね? |
|
for ループを始める前に実行する式のとこには“,”(順次演算子)を使うと2つ以上の式を書けるんだ。
だから、“i=0,n=2”って書くと、
for ループを始める前に i
には 0 が代入されて、n
には 2 が代入されるの。 |
|
※順次演算子については §5.9 参照。 |
|
そーなんだ。
じゃあ…i が 0
から始まって paths.count より小さい間ループするってことだね。 |
|
じゃ paths.count はいくつ? |
|
え〜っと…確か paths[0], paths[1], paths[2]
がそれぞれ第1、第2、第3区間の最終値を表す文字列になってたはずだから、
paths.count は 3 だよね? |
|
※Array(配列)クラスの count プロパティについては §1.14 参照。 |
|
ん、そうだね。じゃループする回数は? |
|
3回、でいいのかな?
なんかループの最後で実行する式が“i++,n+=2”ってなってるけど。 |
|
それもループを始める前に実行する式と同じように順次演算子が使ってあるって考えれば OK だよ。 |
|
じゃあ1回ループするごとに i が 1
増えて n が 2 増えるってこと? |
|
そ。だから3回ループするわけだね。
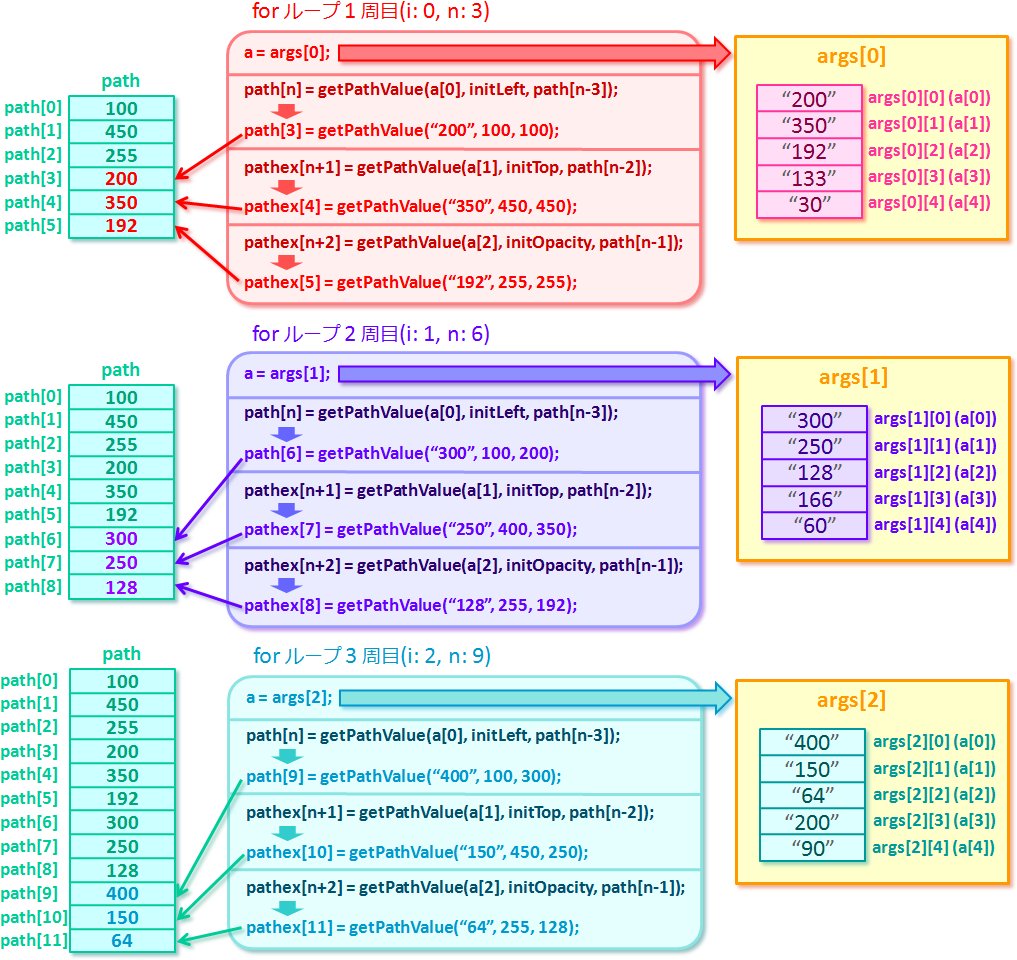
で、まず1周目のループで pathex[2] と
pathex[3] にそれぞれ第1区間の拡大率と回転角の最終値がこんなふうに代入されるの。 |
<for ループ1周目(i=0, n=2 の時)の処理>
|
まず、n が 2 になってて、
a[3](args[0][3])は
"133" になってるから、
pathex[2]、つまり第1区間の拡大率の最終値は
getPathValue("133", 100, 100) の戻り値の
133 になるわけね。 |
|
a[4](args[0][4])は
"30" になってるから、
pathex[3](第1区間の回転角の最終値だよね)は
getPathValue("30", 0, 0) の戻り値の
30 になるってことでいーのかな? |
|
そうそう。
ちなみにもし拡大率が省略されてたら pathex[2] は
getPathValue("", 100, 100) の戻り値の
100 になるよ。 |
|
じゃあ、もし回転角が省略されてたら pathex[3] は
getPathValue("", 0, 0) の戻り値の
0 になるってことだよね。 |
|
そ。
んで for ループ2周目は… |
<for ループ2周目(i=1, n=4 の時)の処理>
|
こんなふうに pathex[4] と pathex[5]
(それぞれ第2区間の拡大率と回転角の最終値ね)に
166 と 60 が代入されて、
for ループ3周目で… |
<for ループ3周目(i=2, n=6 の時)の処理>

|
こうやって pathex[6] と pathex[7]
(それぞれ第3区間の拡大率と回転角の最終値ね)に
200 と 90 が代入されて
pathex 配列が完成するわけね。 |
|
なるほどね…
でもやっぱりこうして見てもややこしいよねぇ。 |
|
まぁ確かにね。
じゃこれで pathex 配列は出来たから、
次のスクリプトを見てくね。 |
|
これって何してるスクリプトなの? |
|
これはね、レイヤを回転させるのか、拡大・縮小するのか、それとも何もしなくていいのかを判断してるスクリプトなの。 |
|
え、どーいうコト? |
|
path 属性に回転角が指定してあったらレイヤを回転させなきゃいけないよね。 |
|
まーそりゃそーだよね。 |
|
でも、回転角は指定されてなくて拡大率だけ指定してあったら、回転させる必要はなくって、
拡大・縮小だけすればいいよね。 |
|
そだね。 |
|
さらに、回転角も拡大率も指定されてなかったら、なんにもしなくていいよね。 |
|
え、レイヤを動かしたりしなきゃいけないでしょ? |
|
あー、まぁそれはそーなんだけど、
レイヤを動かしたり不透明度を変えたりするのは LinearMover
クラスとか SplineMover クラスの仕事だから、
ExtendedMover クラスは何もしなくていいってことね。 |
|
あ、そーゆーコトね。 |
|
で、スクリプトの中に moveFunc
っていう変数(メンバ変数)があるでしょ。 |
|
うん。
“moveFunc = rotate;”とか“moveFunc = resize;”とか書いてあるね。 |
|
moveFunc に rotate
を代入するとレイヤの回転・拡大・縮小処理をやるんだけど、
resize を代入すると拡大・縮小の処理しかやらないんだ。
あと moveFunc が void
だと何もやらないの。 |
|
へぇ、そーなんだ。
でもなんでそんなことやってるの? |
|
基本的に、レイヤを回転する処理の方がレイヤを拡大・縮小する処理より重いから、
レイヤを回転させる必要がない場合は拡大・縮小だけやった方が効率的なの。
あと、もちろん回転も拡大も縮小もしない場合は何もやらないのが一番効率的だよね。 |
|
※レイヤの回転処理には affineCopy メソッド(§9.4 参照)、拡大・縮小処理には stretchCopy メソッド(§9.2 参照)を使用した場合。 |
|
ってことは、処理を効率的にするために moveFunc
に rotate とか resize
を代入してるってコト? |
|
ん、そーゆーコト。
ちなみにこの for ブロックをフローチャートで表すとこんな感じだよ。 |
<この for ブロック 内での処理の流れ>
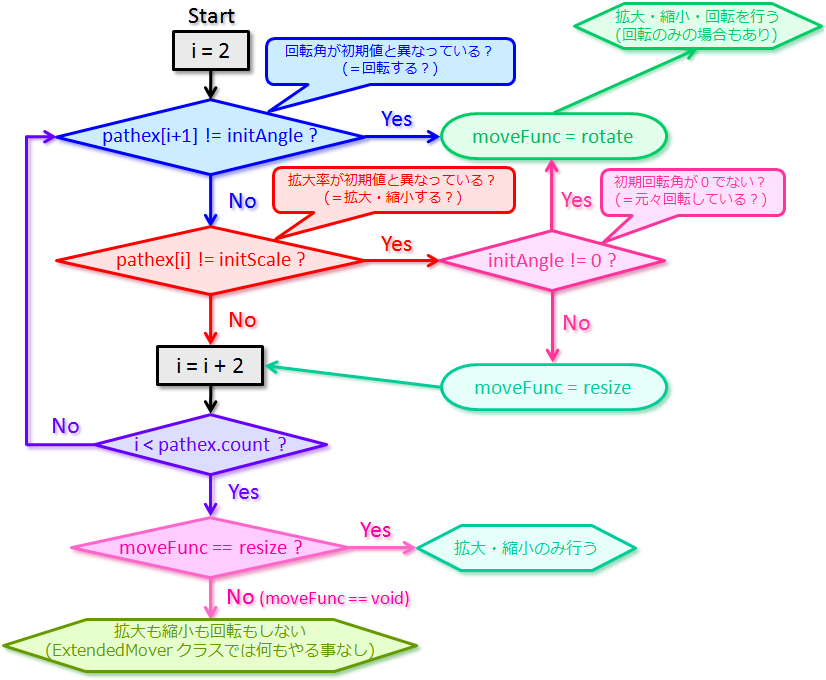
|
フローチャートで表した方がわかりやすいかなーと思ったんだけど…ちょっとややこしかったかな。 |
|
うん、ややこしーね。 |
|
ま、まぁ要するに、path 属性の回転角に初期回転角(initAngle)と違う値が指定されてたら moveFunc に rotate を代入して、
回転角は変わらないけど path 属性の拡大率に初期拡大率(initScale)と違う値が指定されてるって場合は moveFunc に resize を代入するってことだね。
あと回転角も拡大率も変わらないって場合は moveFunc
には何も代入されないから void になるの。 |
|
※処理の都合上、回転角が変わらない場合でも、拡大・縮小を行なう場合かつ初期回転角が 0°でない場合は moveFunc に rotate を代入しています。 |
|
なるほどね。
ところで rotate とか resize ってなんなの? |
|
rotate はレイヤを回転・拡大・縮小するためのメソッドで、
resize はレイヤを拡大・縮小するためのメソッドだよ。
つまり、moveFunc に rotate メソッドとか
resize メソッドへの参照を代入してるってことだね。 |
|
じゃあ moveFunc(); を実行したら、
レイヤを回転する時は rotate メソッドが呼び出されて、
拡大・縮小するだけの時は resize メソッドが呼び出されるってこと? |
|
そうそう。
rotate メソッドと resize
メソッドの中身はまた今度説明するとして、次は for ブロックの後の
if ブロックを見てくね。 |
|
条件が“moveFunc !== void && loadParams.storage !== void”になってるってことは、
moveFunc に rotate か
resize が代入されてて、あと loadParams.storage が
void じゃなかったら if
ブロックの中身が実行されるってことみたいだね。 |
|
つまり、レイヤを回転も拡大も縮小もしない時以外で、
あとレイヤに画像が読み込まれてれば if ブロックの中身が実行されるってことね。 |
|
※レイヤが前景レイヤでない場合は loadParams が空の辞書配列となるため、画像が読み込まれていても if ブロックの中身は実行されません。 |
|
if ブロックの中で新しいレイヤを作ってるみたいだけど? |
|
レイヤを拡大・縮小・回転する時には一時レイヤが必要だからここで作ってるんだ。 |
|
一時レイヤって? |
|
前に stretchCopy メソッドでレイヤを拡大・縮小したり
affineCopy メソッドでレイヤを回転したりしたでしょ。 |
|
※stretchCopy メソッドについては
§9.2、affineCopy メソッドについては
§9.4 参照。 |
|
うん。 |
|
で、stretchCopy メソッドとか
affineCopy メソッドを使う時に「コピー元のレイヤ」ってのを引数に指定したよね。 |
|
確か stretchCopy メソッドとか
affineCopy メソッドって、
他のレイヤに読み込まれてる画像を拡大・縮小したり回転したりしてコピーするんだったよね。 |
|
そ。だから tempLayer っていうレイヤを一時的に作って、
コピー元のレイヤにしたよね。 |
|
そーだったね。 |
|
一時レイヤは基本的にこの tempLayer と同じ使い方をするレイヤなんだ。
ExtendedMover クラスでもレイヤを拡大・縮小したり回転したりするのに
stretchCopy メソッドと affineCopy
メソッドを使うからね。 |
|
じゃあ一時レイヤってコピー元のレイヤってこと? |
|
そう。
じゃ一時レイヤについてはこれで OK かな。 |
|
あ、えっと、一時レイヤを作ってるとこの Layer
クラスのコンストラクタの第1引数が layer.window になってるけど、
これって何なの? |
|
window ってのは Layer クラスのプロパティで、
そのレイヤが所属してるウィンドウオブジェクトを指してるんだ。
だから、前景レイヤの場合(例えば kag.fore.layers[0].window とか)は
kag オブジェクトになってるの。 |
|
じゃあ“refLayer = new Layer(kag, layer);”になるってこと? |
|
まぁそうなるね。
ちなみに第2引数が layer、つまりコピー先レイヤ(動かしたり拡大・縮小・回転するレイヤのことね)だから、
一時レイヤ(コピー元レイヤ)はコピー先レイヤの子レイヤになるってことね。 |
|
※子レイヤ(レイヤの親子関係)については §3.2 参照。 |
|
子レイヤにしてるのって何か理由があるの? |
|
ん〜、特に深い理由はないけど、とりあえず一時レイヤを作る時には親レイヤを指定しなくちゃいけないから、
コピー先レイヤがコピー元レイヤの親レイヤになればいいかなってことで。 |
|
そっか。 |
|
じゃ次いくね。
一時レイヤを作った後に loadImages
メソッドで画像を読み込んでるわけだけど、
どんな画像を読み込んでるかわかる? |
|
※Layer クラスの loadImages メソッドについては §3.3 参照。 |
|
えっとね、引数が loadParams.storage になってるから…
これ確か image タグとか eximage
マクロでレイヤに画像を読み込んだ時に storage 属性に指定されてたファイル名だったよね? |
|
ん、つまりコピー先レイヤに読み込まれてる画像とおんなじ画像を読み込んでるわけね。 |
|
一時レイヤはコピー元レイヤだから、コピー先レイヤと同じ画像にしなくちゃいけないよね。 |
|
そ。あと if ブロックの中に残ってるのは、
レイヤの初期位置を調整してるとこなんだけど… |
|
なんか calcRotateParams ってゆーメソッドを呼び出してるみたいだけど、
これってどんなメソッドなの? |
|
これはね、レイヤが元々回転してる時に、レイヤの位置を補正するためのメソッドなんだ。 |
|
え、レイヤの位置を補正するってどーゆーコト? |
|
んー、そーだね…
例えば… |
<回転しているレイヤ>
|
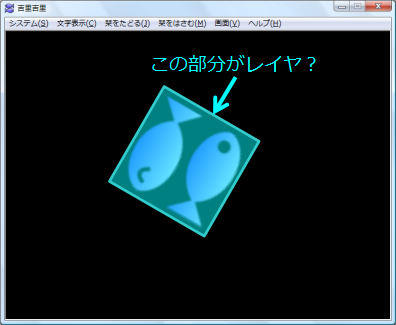
こんなふうに画像が回転してる時は、レイヤはどんな形になってると思う? |
|
なんか唐突だね…
えと、レイヤが回転してるんだから… |
<回転した状態でのレイヤの領域?>
|
こんな感じなんじゃないの? |
|
と思うでしょ?
でも実はレイヤはこういう形にはなってないんだ。 |
|
えっ、違うの? |
|
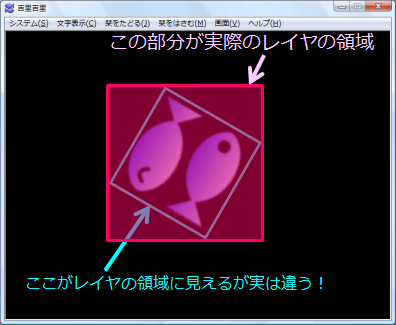
実際にはね… |
<実際のレイヤの領域>
|
この図の□の部分が実際のレイヤの形なんだ。 |
|
えっ、そーなの?
…でもなんでこんな形になってるの? |
|
レイヤの形は必ず回転してない四角形になるからだよ。 |
|
そーなんだ… |
|
つまり、画像を回転するって言っても、実際にはレイヤそのものを回転してるわけじゃなくって、
レイヤの中に表示されてる画像だけを回転してるってワケ。 |
|
へぇ、そーだったんだ。 |
|
で、こうなるとちょっと困ったことが起きちゃうんだよね。 |
|
え、困ったことって? |
|
exmove マクロで画像を拡大・縮小・回転する時は、
レイヤの位置(left と
top のことね)を拡大・縮小・回転の中心の位置で指定することにしてるって言ったでしょ。 |
|
※§9.15 参照。 |
|
そーだったね。 |
|
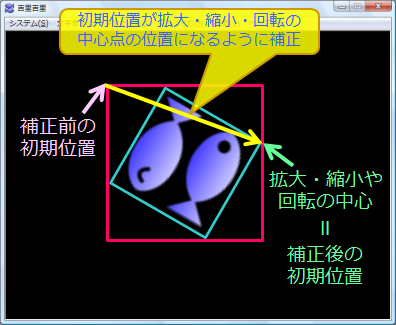
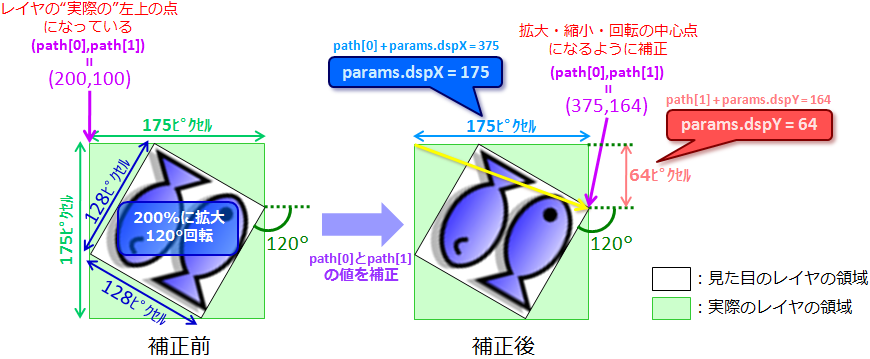
つまり、この例の場合だと… |
<補正前と補正後のレイヤの初期位置>
|
上の図の緑色の矢印で指してる場所が拡大・縮小・回転の中心になるから、
ここが初期位置(初期 left と初期
top)になってないといけないんだけど、
実際にはピンク色の矢印で指してる場所が初期位置になってるんだ。
見ての通り、かなり初期位置がずれちゃってるでしょ? |
|
※シンプル版 exmove マクロの場合、
拡大・縮小・回転の中心は常にレイヤの(見た目上の)左上の点になります。 |
|
そーだねぇ。 |
|
だから、黄色い矢印の分だけ初期位置を補正してあげなくちゃいけないわけ。 |
|
なるほど。 |
|
で、どれだけ補正すればいいかを計算してるのが
calcRotateParams メソッドなの。 |
|
あ、ここでやっと calcRotateParams メソッドが出てくるんだ。 |
|
まぁこの辺もちょっとややこしい話だからね。
で、この calcRotateParams メソッドなんだけど、
詳しい説明は省略させてもらうね。 |
|
え、これだけ色々言っといて肝心の calcRotateParams メソッドは説明しないの? |
|
んー、別にしてもいいんだけど、
回転してる画像の座標計算をやってるメソッドだから、サインとかコサインとかの計算式がいっぱい出てくるよ? |
|
うっ、じゃ、じゃあ省略ってことで… |
|
んじゃ省略させてもらうね。
…けど、完全に省略しちゃったら何やってるのかわかんなくなっちゃうと思うから、
一応簡単に説明しとくね。 |
|
ホントに簡単? |
|
ん、カンタンカンタン。
まず、calcRotateParams メソッドを呼び出した後に path[0] と path[1] にそれぞれ
params.dspX と params.dspY を足してるでしょ。 |
|
path[0] と path[1] って
left と top の初期値だっけ? |
|
※ここのスクリプトで値を代入しています。 |
|
ん、そう。
で、params.dspX と params.dspY ってのは
calcRotateParams メソッドで計算される値で、
それぞれ横方向と縦方向にどれだけ補正すればいいかってのを表す値なの。
例えば… |
<レイヤの初期位置の補正>
|
こんなふうに画像を 200% に拡大して 120°回転した時は、
初期位置(path[0] と path[1])を横方向に
175 ピクセル、縦方向に 64 ピクセルずらせばいいわけね。 |
|
えっと、じゃあ params.dspX と params.dspY
がそれぞれ 175 と 64 になるってこと? |
|
そ。だからここに書いてる通り、
path[0] には params.dspX を足して、
path[1] には params.dspY を足せば、
ちゃんと補正できるってワケ。
そんなに難しくないでしょ? |
|
んー、まーね。
なんか考え方とかは色々ムズカシイけど。 |
|
じゃこれでレイヤの初期位置の補正の話はおしまい。
次はここで path 配列を作ってるんだけど、
やり方は pathex 配列の時と基本的におんなじだから、
説明は省略させてもらうね。
ちなみに path 配列を作る処理を図で表すとこんな感じだよ。 |
<path 配列作成処理の流れ>
|
確かに pathex を作った時と似てる感じだね。 |
|
最終的に出来る path 配列の中身も
move タグで作られる
path 配列の中身と同じになってるでしょ。 |
|
ホントだ。おんなじだね。 |
|
じゃこれで ExtendedMover クラスのコンストラクタは一通りチェックできたね。 |
|
はぁ〜、ホントに長かったねぇ… |
|
だから最初に長くなるって言ったでしょ。 |
|
こんなに長いとは思わなかったよ〜。 |
|
ま、これでもまだ ExtendedMover
クラスの半分くらいしかチェックできてないんだけどね。 |
|
えっ、これだけやってもまだ半分なの!? |
|
ってワケで、ExtendedMover クラスはまだしばらく続くから、
続きはまた次回ね! |